Redis 集群架构-1
使用集群的好处是
- 增加缓存容量
- 提升服务吞吐量
- 容灾
但是什么样的架构才是合适的呢?
主从复制 (Master-SLave)

- 写入和查询分离,减少Master的压力。
- 可以使用master-slave-chains的架构模式,降低master同步数据的压力
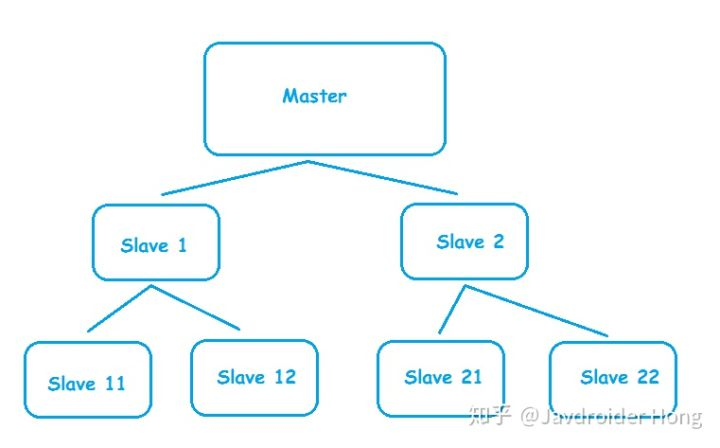
弊端
无法实现真正意义上的高可用。随着数据量增加,节点间数据同步会越来越难以承受。
Redis Cluster
为什么要实现Redis Cluster
- 随着业务量的增加,需要以更高的QPS作为支撑。
- 随着数据量的增加,单纯提升单机的内存已经难以达到业务要求。需要实现分布式,将数据分布在不同服务器上
- 业务流量达到服务器的上限,需要做分流
为啥要做数据分布?
所有的节点都存储全量数据,在业务和数据规模较小时,由于数据同步压力较小,不会过多地影响性能。但是一旦数据达到一定量级,全量数据可能成为压垮机器性能的最后一根稻草。
此时,做合理的数据分区分片,才能更好地保证业务需求。
.png)
常见的数据分布方式
1 | graph LR |
hash分布
hash分布,即通过对数据进行hash运算,然后根据hash的结果将其存放到指定的分片区域。这样可以保证数据能被打散,且分布比较均匀。
节点取余分区
节点取余是比较简单且常见的hash方式。通过对数据取余,来判定存储或读取时的分片位置。.png)
优点:
1 | 客户端分片,逻辑和配置都相对简单 |
缺点:
1 | 当新增或删除节点时,为了平衡数据,会出现较大范围的迁移。 |
一致性hash分区
普通的hash方式,容易在新增机器时,出现大量的hash映射关系失效的问题。一致性hash的出现是对其进行改进。
原理
- 将所有数据当作一个虚拟的token环,token的取值范围自定。为每一个数据节点(node)分配一个token范围值。
- 对每一个存入或者查询的key进行hash运算,被哈希后的结果在哪个token的范围内,则按顺时针去找最近的节点,这个key将会被保存在这个节点上。
.png)
特性
- 单调性(Monotonicity): 新增节点时,原有的请求依旧映射到原有的节点或者新增节点上。
- 分散性(Spread):由于客户端并不清楚后端真实服务器的存在,一致性hash可以避免同一个数据(请求)落在不同节点上的可能。
- 平衡性(Balance):即负载均衡,是指客户端hash后的请求应该能够分散到不同的服务器上去。
扩容
当需要新增节点时,一致性hash能够尽量减少数据迁移的可能。例如:.png)
在n1 和 n2两个节点之间插入节点n5,按照顺时针的规则,新插入的key原本应该保存在n2上会有一部分迁移至n5. 这会大大降低扩容带来的影响。
优点:
- 采用客户端分片方式:哈希 + 顺时针(优化取余)
- 节点伸缩时,只影响邻近节点,数据迁移影响减低
缺点:
- 如果分区不够均与,容易出现hash倾斜,即某个节点处理的负载大大增加。
- 可以通过
均匀一致性hash的方式解决(增加虚拟节点) - 均匀一致性hash的目标是如果服务器有N台,客户端的hash值有M个,那么每个服务器应该处理大概M/N个用户的。也就是每台服务器负载尽量均衡。
- 可以通过
hash槽分区
虚拟槽分区是Redis Cluster采用的分区方式
预设虚拟槽,每个槽就相当于一个数字,有一定范围。每个槽映射一个数据子集。
Redis Cluster中预设虚拟槽的范围为
0-16383
.png)
实现原理:
- 把16384槽按照节点数量进行
平均分配,由节点进行管理 - 对每个key按照
CRC16规则进行hash运算 - 把hash结果对16383进行取余
- 把余数发送给Redis节点
- 节点接收到数据,验证是否在自己管理的槽编号的范围
- 如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
- 如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
Redis Cluster 架构解析
说明
- Redis Cluster是分布式架构,集群中
每个节点都会进行数据的读写操作。 - 节点之间会进行相互通信,即一定时间频率的
meet操作。 - Cluster 会将16384个槽
平均分配给所有节点,由节点自行管理各自的槽数据。同时也知道其他节点管理的槽。 - 客户端访问任意一个节点时,会先对key按照CRC16进行hash,然后对16383进行取余,如果取余结果在当前访问的节点槽,则返回key对应的value,否则返回moved 或 ask 错误,告知客户端应当去哪个节点取数据。
.png)
客户端路由
moved重定向
原理:
- 每个节点通过通信都会共享Redis Cluster中槽和集群中对应节点的关系
- 客户端向Redis Cluster的任意节点发送命令,接收命令的节点会根据CRC16规则进行hash运算与16383取余,计算自己的槽和对应节点
- 如果保存数据的槽被分配给当前节点,则去槽中执行命令,并把命令执行结果返回给客户端
- 如果保存数据的槽
不在当前节点的管理范围内,则向客户端返回moved重定向异常 - 客户端接收到节点返回的结果,如果是moved异常,则
从moved异常中获取目标节点的信息 - 客户端向目标节点发送命令,获取命令执行结果
1 | graph LR |
ask重定向
当客户端向某个节点发送命令,节点向客户端返回moved异常,告诉客户端数据对应的槽的节点信息
如果此时正在进行集群扩展或者缩空操作,当客户端向正确的节点发送命令时,槽及槽中数据已经被迁移到别的节点了,就会返回ask,这就是ask重定向机制。
.png)
原理
- 客户端向目标节点发送命令,目标节点中的槽已经迁移支别的节点上了,此时目标节点会返回ask转向给客户端
- 客户端向新的节点发送Asking命令给新的节点,然后再次向新节点发送命令
- 新节点执行命令,把命令执行结果返回给客户端
moved异常与ask异常的相同点和不同点
| 类型 | 相同点 | 不同点 |
|---|---|---|
| moved | 客户端重定向 | 槽已经确定迁移,即槽已经不在当前节点 |
| ask | 客户端重定向 | 槽正在迁移中 |
客户端
为了追求更高的性能,客户端应当缓存Cluster Slots及对应的node信息,以减少由于moved和ask带来的多次交互问题。