Redis常用数据结构
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库。
官方线上Tutoral:http://try.redis.io/
Redis具有以下特点:
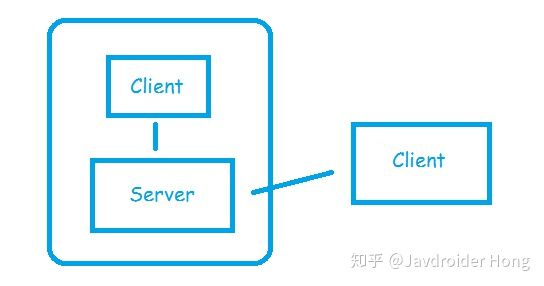
- redis是C/S架构
- Redis的Server是
单线程服务器,基于Event-Loop模式来处理Client的请求。
使用单线程的好处包括:
- 不必考虑线程安全问题。很多操作都不必加锁,既简化了开发,又提高了性能;
- 减少线程切换损耗的时间。
- 弊端:无法利用多处理器的性能。
常用的数据结构和业务场景
String-字符串
最简单的key-value类型,value可以是String或数字(interger)
- 常用于存储一些简单的键值。比如用户登陆信息,配置信息等。
- 常用操作是incr/decr操作,即自减/自增操作。调用它是原子性的。
Hash(hset)
常用命令
- hset(key, field, value):向名称为key的hash中添加元素field<—>value
- hget(key, field):返回名称为key的hash中field对应的value
- hmget(key, field1, …,field N):返回名称为key的hash中field i对应的value
- hmset(key, field1, value1,…,field N, value N):向名称为key的hash中添加元素field i<—>value i
- hincrby(key, field, integer):将名称为key的hash中field的value增加integer
- hexists(key, field):名称为key的hash中是否存在键为field的域
- hdel(key, field):删除名称为key的hash中键为field的域
- hlen(key):返回名称为key的hash中元素个数
- hkeys(key):返回名称为key的hash中所有键
- hvals(key):返回名称为key的hash中所有键对应的value
- hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
数据结构
redis 中 hash 底层使用 hash value挂链表的方式实现。即,相同hash key的value以链表的形式存储。
hashtable结构体定义:
1 | typedef struct dictht { |

适合存储对象。即非序列化数据。
为什么呢?
- Redis中的哈希散列是一个string类型的field和value的映射表,它的增删操作的复杂度平均为O(1)。
- 哈希的内部结构包含
zipmap和hashtable两种。- hashtable 适合存储对象。
- zipmap 则是当hash表数据较少时,使用zipmap存储,节省内存空间。操作复杂度O(n)
Redis 中HashTable实际上是对字典进行操作。字典数据结构如下:
1 | typedef struct dict { |
.png)
rehash
何时需要rehash
当哈希表的大小不能满足需求,就可能会有两个或者以上数量的键被分配到了哈希表数组上的同一个索引上,发生冲突(collision)。
判断条件:哈希表的负载因子不在合适的范围内
复杂度:O(n)
负载因子: hashtable已使用结点数量除上哈希表的大小
1 | load_factor = ht[0].used / ht[0].size |
扩容条件:load_factor 大于5,需要扩容。
- 扩容时,会为ht[1]分配空间,大小为ht[0].used *2 的 2 的幂
- 将 ht[0] 中的键值rehash到ht[1]上,rehash就是重新计算hash值,插入到ht[1]中。
- 当 ht[0] 包含的所有键值对全部 rehash 到 ht[1] 上后,释放 ht[0] 的内存空间, 将 ht[1] 设置为 ht[0],并且在 ht[1] 上新创件一个空的哈希表,为下一次 rehash 做准备;
缩容条件:元素个数低于数组长度的 10%
- 缩容时,为ht[1]分配空间,大小等于 max( ht[0].used, DICT_HT_INITIAL_SIZE )
渐进式rehash
由于rehash是一个比较耗时耗资源的操作,所以会分多次,渐进式,断续进行rehash操作。
标志位:
rehashidx
- 该标志位位于是dict结构体的属性字段。
- 当rehashidx为-1时表示不进行rehash,当rehashidx值为0时,表示开始进行rehash
- 在rehash期间,每次对字典的添加、删除、查找、或更新操作时,都会判断是否正在进行rehash操作,如果是,则顺带进行单步rehash,并将rehashidx+1。
- rehash时进行完成时,将rehashidx置为-1,表示完成rehash。
Hash 算法
Thomas Wang’s 32 bit Mix函数,对
整数进行哈希,该方法在dictIntHashFunction中实现使用MurmurHash2哈希算法对
字符串进行哈希,该方法在dictGenHashFunction中实现使用基于djb哈希的一种简单的字符串哈希算法,该方法在dictGenCaseHashFunction中实现。
计算 索引index
1
idx = h & d->ht[table].sizemask;
总结
结构:
- 一个字典对象代表了一个dict的实例,
- 一个dict中包含了两个dictht组成的哈希表素组和一个指向dicType的指针。定义两个dictht的作用主要是为了扩容过程中,能够保证读取数据的一致性,
- dicType中定于了一系列的函数指针。
- 每个dictht中,存在一个dicEntry变量,可以看做是字典数组,也就是俗称中的bucket桶,存放数据的主要容器。每个dictEntry中,除了包括key和value的键值对以外,还包括指向下一个dictEntry对象的指针。
哈希算法:redis主要提供了三种Hash算法
rehash:rehash发生在扩容或缩容阶段,扩容是发生在元素的个数等于哈希表数组的长度时,进行2倍的扩容;缩容发生在当元素个数为数组长度的10%时,进行缩容。
Set - 集合
- 具有去重的功能,内部的键值对是无序的唯一的。
- 它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值NULL
- 删除元素,元素占用内存立即回收
常用命令
- sadd(key, member):向名称为key的set中添 加元素member
- srem(key, member) :删除名称为key的set中的元素member
- spop(key) :随机返回并删除名称为key的set中一个元素
- smove(srckey, dstkey, member) :将member元素从名称为srckey的集合移到名称为dstkey的集合
- scard(key) :返回名称为key的set的基数
- sismember(key, member) :测试member是否是名称为key的set的元素
- sinter(key1, key2,…key N) :求交集
- sinterstore(dstkey, key1, key2,…key N) :求交集并将交集保存到dstkey的集合
- sunion(key1, key2,…key N) :求并集
- sunionstore(dstkey, key1, key2,…key N) :求并集并将并集保存到dstkey的集合
- sdiff(key1, key2,…key N) :求差集
- sdiffstore(dstkey, key1, key2,…key N) :求差集并将差集保存到dstkey的集合
- smembers(key) :返回名称为key的set的所有元素
- srandmember(key) :随机返回名称为key的set的一个元素
使用场景
- 可以统计访问网站的所有独立 IP
- 好友推荐的时候,根据 tag 求交集,大于某个 threshold 就可以推荐
SortSet - 有序集合
和Set相比,Sorted Sets是将 Set 中的元素增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列
使用场景
- 需要在插入就进行排序的业务场景。
- 可以通过设置score的方式,区分重要任务和普通任务
List -列表
redis使用双端链表实现的 List
使用场景
- 消息队列。利用Lists的push的操作,将任务存储在list中,然后工作线程再用pop操作将任务取出进行执行。
其他
watch 机制
基于CAS(Compare and Swap)机制,实现事务过程中的通过对比数据的一致性来判断Transaction的执行。
由于实现比较简单,容易出现ABA问题。
- 线程1 Watch 数据data=A。开始执行事务
- 线程2 先将data修改为B,然后再将data修改为A
- 线程1 并未察觉data数据的变化,会完成对事务的操作。